

Google Veo 2 – це нова модель штучного інтелекту, здатна генерувати короткі відеоролики високої якості на основі текстового опису. Розроблена підрозділом Google DeepMind, ця нейромережа позиціонується як прорив у сфері text-to-video і фактично відповідь Google на аналогічні проєкти на кшталт OpenAI Sora. Всього за кілька хвилин після введення користувачем текстового запиту Veo 2 здатна створити реалістичний відеофрагмент, який інколи важко відрізнити від справжніх відеозйомок. Розгляньмо, як влаштована ця технологія, її можливості, прикладні сценарії та чим Veo 2 відрізняється від інших платформ, таких як Sora чи Runway ML.
Технічні особливості та принцип роботи Veo 2
Veo 2 – найсучасніша на сьогодні відеогенеративна модель від Google. В основі її роботи – глибока нейронна мережа, навчена на величезному масиві відео та відповідних описів до них. Це означає, що модель проаналізувала безліч прикладів відеосцен та текстових пояснень до них, щоб навчитися «розуміти», як зі словесного опису сформувати послідовність кадрів. За словами компанії, Veo 2 покращила розуміння фізики реального світу та нюансів людського руху і міміки, тож вона рідше генерує невірні або дивні деталі у відео. Завдяки цьому результати мають вищу реалістичність: модель правильніше передає закони руху об’єктів, пропорції людей і тварин, тіні та відображення.
Одне з ключових удосконалень – «кінематографічне» мислення моделі. Veo 2 розуміє мову операторів і режисерів: у текстовому запиті користувач може вказати жанр сцени, тип камери чи об’єктива, кути зйомки або спецефекти – і модель врахує ці вказівки. Наприклад, якщо попросити «низький ракурс, 18 мм об’єктив: машина дрифтує, залишаючи за собою шлейф світла й диму від шин», Veo 2 налаштує «віртуальну камеру» відповідно – зніматиме від землі, широкоекранно, захоплюючи драматичний дріфт авто з ефектними світловими смугами позаду. Подібні детальні підказки (як-от згадка про певний фокус чи глибину різкості) дозволяють отримати задуманий художній ефект у згенерованому відео.
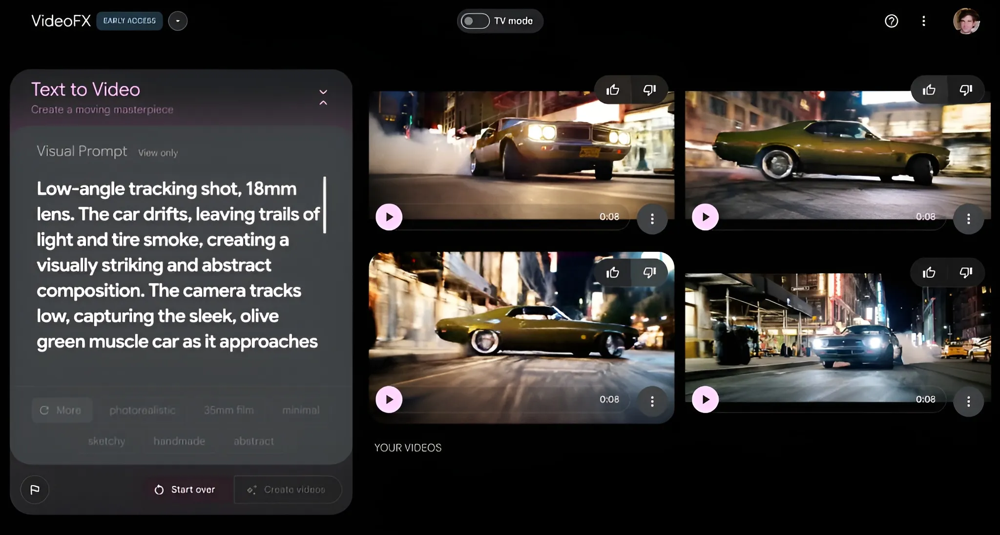
Приклад інтерфейсу Google VideoFX з моделлю Veo 2: текстовий запит (ліворуч) містить кінематографічні деталі зйомки, а праворуч – кадри з отриманого 8-секундного відео про автомобіль, що дрифтує вночі. Veo 2 точно слідує інструкціям щодо ракурсу (низька точка зйомки), типу об’єктива та атмосферних ефектів, демонструючи реалістичний рух і світлотіні згідно з описом.
Якість відео та формат. Модель Veo 2 здатна генерувати відео з роздільною здатністю аж до 4K (4096×2160) пікселів при потребі, а тривалість кліпу може сягати двох і більше хвилин. Це значний стрибок у порівнянні з попередніми поколіннями генераторів: для прикладу, та сама OpenAI Sora обмежена створенням роликів до ~20 секунд і роздільністю до 1080p. Втім, наразі звичайним користувачам Veo 2 доступна в обмеженому режимі – через експериментальні сервіси Google.
У межах інструменту VideoFX (Google Labs) або чатбота Gemini модель зараз генерує приблизно 8-секундні відеофрагменти формату 1280×720 px (720p). Відео стандартно має ландшафтну (горизонтальну) орієнтацію 16:9. Після генерації ролик можна завантажити на пристрій у вигляді відеофайлу (формату .mp4) або поділитися ним, як зазначає огляд Android Authority. Google поступово нарощує доступ до Veo 2: з часом обіцяють відкрити підтримку довших відео та вищих роздільностей для ширшого загалу, а також інтегрувати модель у продукти на кшталт YouTube Shorts.
Архітектура та навчання. Технічні деталі реалізації Veo 2 компанія повністю не розкриває, але відомо, що модель навчалась на величезному датасеті «відео + текстовий опис» високої якості. Не виключено, що серед джерел даних були ролики з YouTube та інших платформ, адже Google володіє YouTube і має до нього доступ. Отримавши мільйони прикладів, нейромережа вивчила закономірності між словами та візуальними подіями. Коли користувач вводить текстовий підказ, ця складна модель генерує нові кадри відео, крок за кроком «фантазуючи» розвиток сцени на основі набутого досвіду.
Судячи з описів, Veo 2 може бути побудована на сучасних архітектурах глибокого навчання: можливо, поєднуючи дифузійні моделі з темпоральною послідовністю кадрів або трансформерні нейромережі, здатні генерувати відеопотік. Такий підхід дозволяє моделі досягати state-of-the-art результатів у порівнянні з іншими генераторами відео – це підтверджено тестами з оцінкою людьми, де Veo 2 випередила конкурентів за загальною якістю і відповідністю відео до заданого опису.
Варто зазначити, що всі згенеровані Veo 2 ролики позначаються спеціальним водяним знаком на рівні даних: Google вбудовує в кожен кадр невидимий маркер за технологією SynthID, який дозволяє згодом визначити, що відео створене ШІ. Це зроблено з міркувань безпеки та відповідального використання, щоб запобігти дезінформації та неправомірному присвоєнню фейкових відео. Алгоритм SynthID стійкий до базових змін ролика, хоча, як і всі водяні знаки, не є абсолютно непорушним.
Google підкреслює, що розвиток Veo 2 відбувався обережно і поступово саме задля відпрацювання безпечної видачі та високої якості моделі. Також система має фільтри контенту на боці сервера: певні заборонені або ризиковані запити (наприклад, відверто насильницькі чи порнографічні сцени) будуть відхилені моделлю, і користувачу потрібно перефразувати запит. Компанія заявляє про наявність місячного ліміту на кількість створених відео (щоб уникнути надмірного навантаження), хоча точні цифри не розголошуються.
Практичне застосування моделі Veo 2
Хто і як може використовувати Veo 2? Наразі сервіс доступний для обмеженого кола ентузіастів та творчих користувачів через програму раннього доступу. Зокрема, спробувати Veo 2 можуть підписники тарифу Google One AI Premium (приблизно $20/міс), які отримують доступ до можливостей ШІ у продуктах Google. У веб-інтерфейсі або мобільному додатку чатбота Gemini з’явилась опція вибрати модель Veo 2 у випадаючому списку і ввести текстову підказку для генерації відео.
Користувачу достатньо описати сцену своїми словами (англійською чи іншою мовою, які підтримує Gemini) і зачекати кілька хвилин, поки нейромережа збереже згенерований ролик. Готове відео можна завантажити або одразу поділитися з друзями. Це відкриває надзвичайно широкий простір для креативності: будь-хто без навичок зйомки чи анімації може «намалювати» відео текстом і швидко отримати результат.
На практиці Veo 2 вже використовують для різних цілей. Контент-кріейтори та блогери можуть генерувати короткі відеовставки для своїх роликів, інтро або фантазійні сцени, економлячи на реальних зйомках. Маркетологи та рекламні агенції здатні швидко створювати концепт-відео для продуктів чи візуалізації ідей: наприклад, за лічені хвилини змоделювати кліп в стилі автомобільного рекламного ролика чи демонстрацію інтер’єру, не наймаючи знімальну групу.
Художники та режисери можуть застосовувати Veo 2 для превізуалізації (previz) – створення чорнового відеоряду за сценарієм, щоб уявити як може виглядати сцена в кіно. Це корисно на етапі планування: буквально «генерувати сторіборди, що рухаються». Також Veo 2 приваблює освітян і наукових популяризаторів: легко отримати навчальний кліп із довільної тематики (скажімо, змоделювати виверження вулкана чи історичну сцену) для ілюстрації лекції або статті. Візуальні можливості, які раніше вимагали команд професіоналів, тепер доступні через простий інтерфейс ШІ.
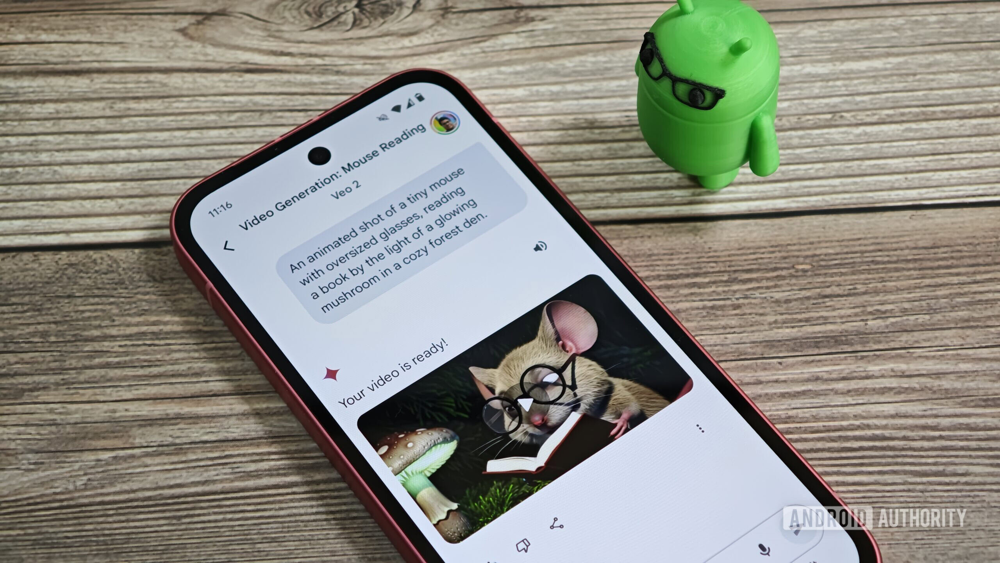
Інтерфейс чатбота Gemini з увімкненою моделлю Veo 2 на смартфоні: користувач ввів запит англійською (“An animated shot of a tiny mouse with oversized glasses, reading a book by the light of a glowing mushroom in a cozy forest den” – опис маленького мишеняти з книжкою при світлі грибочка), і за кілька хвилин з’явився згенерований 8-секундний ролик. На зображенні – кадр із цього відео: мультяшний мишеня у окулярах читає книжку. Veo 2 впоралась із таким казковим сценарієм, надавши цілком придатний мультфільмований результат.
Окрім генерації відео «з нуля» на основі тексту, Veo 2 пропонує й інші цікаві інструменти. Зокрема, функція Whisk Animate дозволяє брати статичні зображення і оживляти їх, перетворюючи на короткі 8-секундні анімації. Наприклад, можна завантажити фотографію інтер’єру і додати рух: модель створить ілюзію, ніби камера плавно об’їжджає кімнату, або статичному портрету додасться миготіння очей і легка посмішка.
Такі можливості будуть корисні дизайнерам, які хочуть презентувати роботу клієнту у динамічному вигляді, або просто користувачам для розваги – «оживити» улюблене фото. Наразі Whisk Animate доступна експериментально через платформу Google Labs для підписників Gemini Advanced. Цей інструмент побудований на базі окремої моделі Google Whisk, що спеціалізується на генерації зображень за описом, але доповнений анімаційним компонентом.
Вже зараз ентузіасти діляться прикладами згенерованих Veo 2 відео в інтернеті. Деякі результати вражають якістю: людина, не знаючи контексту, може прийняти такий ролик за справжній. Скажімо, Veo 2 впевнено відтворює природні явища (плескіт хвиль, захід сонця), рух тварин і людей (пробігання собаки, жестикулювання ведучого) тощо. В оглядах зазначають, що модель добре дає раду навіть складним текстурам і рідинам: були продемонстровані сцени, де повільно ллється кленовий сироп на млинці або наливається кава – і Veo 2 точно передала в’язкість рідини, світлові переломи та відблиски.
Так само модель якісно генерує анімаційні, мультиплікаційні сюжети: наприклад, кліп у стилі Pixar про казкового пса чи мишеня виходить переконливо стилізованим. У цих випадках перевага Veo 2 в тому, що вона уважно слідує опису: що б ви не написали – від “червоний спорткар їде вздовж узбережжя” до “середньовічний лицар б’ється з драконом у дощову ніч” – модель спробує максимально втілити саме ваш сценарій. Це відрізняє її від традиційних інструментів відеомонтажу, де ви обмежені наявними знятим матеріалом або шаблонами.
Втім, попри значний прогрес, Veo 2 не всесильна – подекуди результати видають штучність. Наприклад, оглядачі помітили, що в згенерованих людях чи тваринах інколи можна побачити ефект «неживих очей» – погляд виглядає порожнім, ляльковим. Складні сцени з великою кількістю об’єктів у русі можуть мати артефакти: елементи фону інколи «пливуть» чи зливаються між собою в нелогічний спосіб. Наприклад, в одному тестовому відео пішоходи на задньому плані ніби зливалися з будівлями, порушуючи перспективу. Такі недоліки характерні для меж можливостей сучасних генераторів: модель може втрачати узгодженість і цілісність при тривалих складних сценах.
Розробники з Google DeepMind визнають ці обмеження: Veo 2 поки що добре тримає заданий образ протягом пари хвилин, але може збитися на довгих відтинках чи за дуже заплутаних сюжетів. Так само підтримка сталого вигляду персонажів (щоб, наприклад, герой у кадрі завжди мав однакове обличчя) лишається викликом. Команда продовжує працювати над вдосконаленням моделі, співпрацюючи з митцями й творцями контенту, які тестують Veo в реальних проектах та надають зворотний зв’язок.
Порівняння Veo 2 з Sora, Runway ML та іншими платформами
Штучний інтелект для генерації відео – гаряча галузь, і окрім Google у ній є декілька гравців. Розгляньмо, в чому Veo 2 виграє, а в чому поступається своїм основним конкурентам – OpenAI Sora та рішенням від Runway ML, а також згадаємо інші схожі розробки.
Veo 2 vs OpenAI Sora
OpenAI Sora з’явилася раніше (її анонсували близько середини 2024 року) і стала однією з перших доступних широкому загалу text-to-video систем. Вона інтегрована у екосистему OpenAI: зокрема, доступ до Sora мають передплатники ChatGPT Plus у вигляді окремого режиму генерації відео. За функціоналом Sora дещо відрізняється від Veo 2. Вона орієнтована на короткі кліпи: максимальна тривалість становить ~20 секунд, а роздільна здатність – 1080p (Full HD) у преміум-режимі.
Тобто Sora генерує коротші ролики, але трохи вищої роздільності, ніж наразі доступно у Veo 2 через Google Labs (де ліміт 720p). Однак Veo 2 як технологія має більший потенціал масштабу – підтримка 4K і довших відео дає їй запас міцності на майбутнє, тож коли ці опції стануть публічними, перевага в чіткості та тривалості буде на боці Veo 2.
Sora дозволяє задавати текстові підказки і навіть завантажувати зображення чи відеофрагменти як референси стилю або об’єктів. Це означає, що користувач може, наприклад, завантажити свій відеокліп і попросити Sora змінити в ньому щось: такий режим редагування реалізовано через функції “Remix”, “Loop”, “Blend”, які є одними з інноваційних можливостей Sora.Veo 2, натомість, більше сконцентрована на генерації «з чистого аркуша» і надає детальні кінематографічні налаштування (через текст) замість інструментів редагування вже існуючого відео.
Тобто, Sora можна розглядати як інструмент для творчих експериментів з відео: вона швидко (відносно Veo) генерує короткі сцени, дозволяє користувачу погратися з варіаціями (перемішати, зациклити, поєднати відео), однак іноді страждає якість і реалістичність. За відгуками, Sora нерідко видає артефакти: неправдоподібні рухи, спотворені об’єкти чи аномалії у відео, особливо коли сцена складна або містить активну взаємодію об’єктів. Відомо, що Sora має труднощі з відтворенням фізики – наприклад, моделюванням гравітації чи реалістичних зіткнень, через що результати можуть виглядати менш переконливо.
Veo 2 у цих аспектах перевершує конкурента. Її сильна сторона – реалізм та фізична правдоподібність. Модель Google краще дотримується умов складного запиту, з більшою точністю симулює рух, взаємодію об’єктів, рідини, тіні тощо. Як наслідок, відсоток придатних кліпів з Veo 2 вищий: більше генерацій виходять вдалими і відповідають задуму користувача.
В одному публічному порівнянні експерт навіть образно зазначив, що порівнювати Sora і Veo 2 – це як «порівнювати велосипед і зореліт» за можливостями. Це, звісно, перебільшення, але тенденція зрозуміла: Veo 2 краще для фотореалістичних або професійних завдань, коли потрібна максимальна якість, нехай і за більший час обчислень, тоді як Sora більше підходить для швидкого контенту і розваг, де можна змиритися з певними спрощеннями заради оперативності.
Разом з тим, дружність до користувача у Sora теж на висоті. Її інтеграція в ChatGPT означає знайомий інтерфейс і легкий старт для мільйонів користувачів платформи OpenAI. Sora забезпечує швидший цикл генерації: коротший хронометраж дозволяє обчислити результат трохи швидше, тож для експрес-ідеї або соцмережного посту це зручніше. До того ж, Sora вже має згадані інтерактивні інструменти редагування, які Veo 2 поки не надає (у Veo немає режиму, де можна завантажити своє відео і змінити його елементи).
Тому оптимальний вибір залежить від потреб: якщо вам потрібно кіно-якість, високий реалізм і ви готові почекати – Veo 2 буде кращим вибором; якщо важлива швидкість і ігрова взаємодія з контентом – Sora може бути зручнішою для експресії коротких ідей.
Veo 2 vs Runway ML та інші платформи
Runway ML – відома платформа, що пропонує інструменти генеративного AI для відео та графіки. Ще на початку 2023 року Runway запустила модель Gen-2, яка вміла створювати кількасекундні відео за текстовим описом, ставши одним із перших доступних сервісів такого роду. Однак за своїми можливостями Gen-2 значно скромніша: типовий ролик тривав ~4 секунди, а якість була на рівні 480p–720p (хоча згодом додали опцію умовного “HD”).
Користувачі знаходили творчі способи подовжувати відео (наприклад, послідовно зшиваючи кілька генерацій або сповільнюючи кадри), але це вже вимагало додаткових зусиль. Новіша Gen-3 (у режимі альфа-тестування) та анонсована Gen-4 від Runway обіцяють поліпшення – зокрема, підтримку різних аспектних співвідношень і стабільнішу якість, проте роздільна здатність все ще обмежена на рівні 720p для прямої генерації (з подальшим програмним підвищенням деталізації до 4K за бажанням).
Тобто в плані чіткості зображення та довжини кліпу Veo 2 суттєво випереджає поточні можливості Runway. З іншого боку, Runway ML – це цілий набір інструментів, де є не тільки text-to-video: там інтегровані засоби для стилізації відео, заміни фонів, створення ефектів тощо, які можуть доповнювати роботу генератора. Тому професіонали відеомонтажу можуть комбінувати Veo 2 і Runway в своєму конвеєрі: наприклад, спочатку згенерувати сцену через Veo, а потім доопрацювати її в Runway, наклавши текст, графіку чи інші доопрацювання.
Серед альтернативних платформ варто згадати і дослідницькі проекти великих компаній. У 2022 році Meta (Facebook) показала прототип AI-системи Make-A-Video, що могла генерувати короткі відео, а також існував проект Phenaki для створення довших відео з послідовності описів. Проте ці напрацювання поки не перетворились на публічні сервіси. Натомість, в Китаї і інших країнах з’являються власні моделі: наприклад, дослідницький інструмент від Alibaba ModelScope Text2Video доступний відкрито, але він генерує зовсім короткі кліпи низької роздільності і радше демонструє концепт, ніж готовий продукт.
Є також стартапи, що займаються генерацією або редагуванням відео за допомогою ШІ – Synthesia, Kaiber, Wonder Studio та інші – однак багато з них спеціалізуються на вузьких задачах (наприклад, Synthesia генерує відео з віртуальними ведучими з тексту, а не довільні сцени). На тлі цього Google Veo 2 наразі виглядає одним із найбільш просунутих і універсальних рішень для текстово-зорієнтованої генерації відеоконтенту.
Переваги Veo 2 у порівнянні з конкурентами можна підсумувати так: вища потенційна якість (4K), довша тривалість роликів, краща фізична достовірність і деталізація, а також унікальна можливість керувати «камерою» через текст (задаючи ракурси, стилі зйомки). Це робить її привабливою для професійних творців контенту, які прагнуть кінематографічного рівня від AI-генерації.
Обмеження та недоліки Veo 2 полягають у поки що звуженій доступності (не кожен бажаючий може просто зараз скористатися сервісом – потрібно отримати доступ через Google Labs чи платну підписку), а також у високих вимогах до ресурсів: складні запити потребують більше часу на обчислення, і модель все ще може давати збої на дуже комплексних сценах (втрачаючи узгодженість або чіткість дрібних деталей). Sora від OpenAI, навпаки, більш доступна широкій аудиторії, інтегрована у популярний сервіс ChatGPT і має нижчий поріг входження.
Проте за це доводиться платити дещо нижчою реалістичністю та гнучкістю результату. Runway ML доступна як окремий застосунок і теж не вимагає від користувача технічних знань, але її вихідна якість поки що помітно поступається Veo 2.
Висновки
Google Veo 2 представляє собою значний крок вперед у генеративних можливостях штучного інтелекту. Ще кілька років тому ідея, що можна описати сценою одним-двома реченнями і отримати короткий фільм, здавалася фантастикою. Тепер це реально завдяки поєднанню потужних алгоритмів і колосальних обсягів даних, на яких вони навчаються.
Veo 2 вже демонструє, що ШІ може творити маленькі «відеошедеври» на льоту – від реалістичних пейзажів до анімованих історій – розширюючи межі креативності для всіх нас. Звичайно, технологія ще розвивається: іноді ролики нагадують радше сюрреалістичний сон, ніж реальність, і потрібно відповідально ставитися до її використання (зважаючи на етичні питання та ризики дезінформації). Утім, науково-популярний інтерес до таких систем цілком виправданий – вони демонструють, як стрімко штучний інтелект наближається до розуміння та відтворення все складніших аспектів нашого світу.
Якщо сьогодні Veo 2 може за хвилини згенерувати 8-секундний відеофрагмент, то цілком можливо, що в недалекому майбутньому вдосконалені моделі зможуть створювати для нас повноцінні сцени та навіть короткометражні фільми за одним лише задумом, відкриваючи еру нового, демократизованого кіновиробництва.